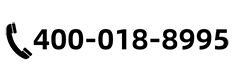最新动态
COMPANY NEWS
全站搜索
COMPANY NEWS
这几天,你的朋友圈大概率被一只”小龙虾”刷屏了。
OpenClaw,让全网沸腾——腾讯大厦前排队”装虾”,创业者们连夜讨论AI智能体的商业化落地,企业采购群里GPU订单飞速滚动。
AI军备竞赛,又热了一个量级。
但在这场狂欢中,一个残酷的现实正在上演:绝大多数企业买回来的GPU,有一半以上的时间在”发呆”。
一个配备64块GPU的AI集群,建设成本高达2100万,实际只承担着500万左右的工作负载。
企业以为自己缺的是GPU,但真正拖后腿的,其实是一个长期被忽视的环节——存储架构。
01 一个正在恶化的行业困境
TrendForce最新数据显示:2026年Q1常规DRAM合约价涨幅预测将大幅上调至90-95%,企业级SSD价格涨幅预计达53-58%,均创历史新高。
这意味着什么?
“用硬件堆算力”这条老路,已经走不通了。每一位IT决策者都必须回答:在存储资源结构性紧缺的时代,如何让AI依然高效运行?
02 三个被低估的效率黑洞
我们观察到,AI基础设施的效率损耗,几乎都藏在同样的三个地方。
01GPU在”等数据”。训练阶段,存储供给数据速度跟不上,GPU频繁空转。花大价钱买来的算力卡,相当一部分时间在”发呆”。
02推理时内存”爆仓”。 大模型上下文窗口扩展至百万级Token,KV Cache体积远超GPU显存极限。内存耗尽就必须重新计算——既耗时又烧钱。
03数据孤岛制造隐形浪费。 数据采集、训练、推理各成体系,同一份数据被反复复制,冗余严重,管理复杂。
AI时代最大的浪费,不是没有算力,而是有算力却用不出来。
03 问题的根源在存储架构逻辑
在我们看来,这三个问题的共同根源是——传统存储架构,根本不是专门为AI工作负载设计的。
传统存储应对的是相对单一的负载类型。而AI工作负载截然不同:数百节点大规模并行读取、频繁的检查点写入、多租户带宽争夺……这些挑战叠加在一起,是传统存储从未被设计去应对的。
所以”重新设计存储架构的底层逻辑”才是根本,这正是我们一直在做的事——不是卖一台更快的设备,而是从AI应用场景出发,重新思考基础设施每一个环节该怎么建。
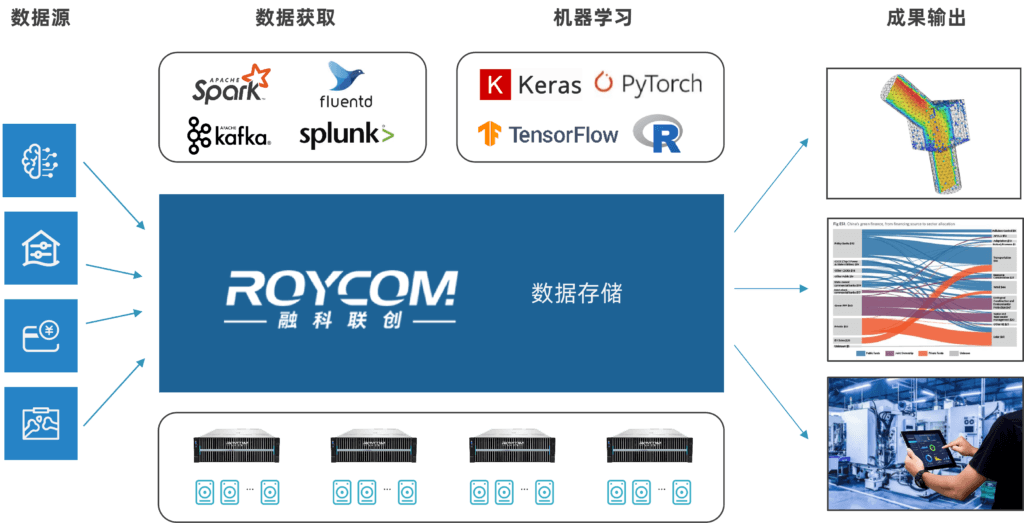
基于这个判断,融科联创RS8000系列存储产品给出了三套针对性解法。
解法一分层优化
让每一分存储投入指向真正的性能需求
AI环境中的数据天然分层:热数据需要极致性能,温数据需要适度性能,冷数据侧重容量和耐久性。融科存储通过”介质无关”的并行架构,统一支持NVMe、标准SSD及大容量HDD的透明混用,系统根据负载自动平衡数据分布。
对客户来说:GPU利用率保持95%以上,高端SSD需求减少40-60%,存储成本支出最高降低70%。不是牺牲性能换成本,而是用架构级的效率设计,让每一分投入都花在该花的地方。

解法二RKCache
重构存储逻辑,释放GPU真实潜能
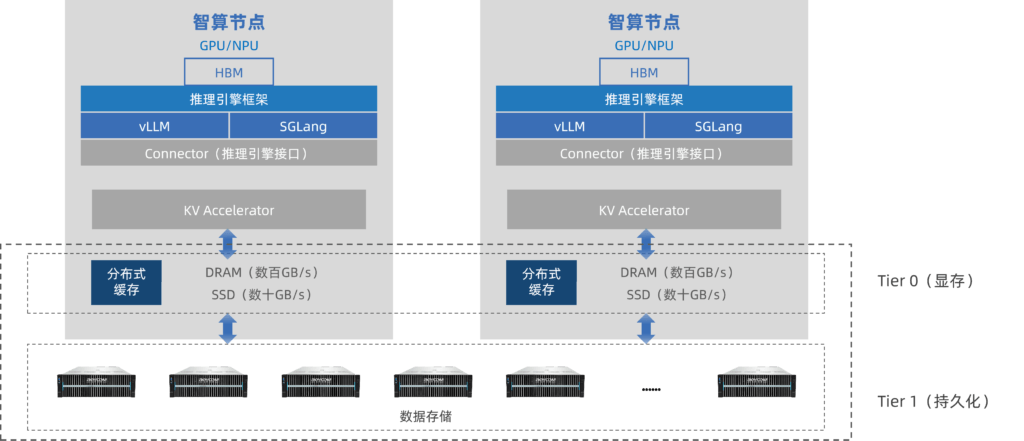
融科自研RKCache将KV Cache从昂贵的HBM扩展至高性能NVMe存储,所有GPU共享一致的全局上下文池,消除协调开销。实测数据:相比开源推理框架vLLM,单台服务器Token吞吐量提升约一倍;TPOT单令牌时延降低50%;TTFT相比于原生方案降低了58%。
这意味着:过去因为显存不够而被迫降低并发、牺牲响应速度的场景,现在可以流畅运行。企业不需要为了扩展推理能力而不断购买更多GPU——用软件定义的智能,替代硬件堆叠的蛮力。
解法三统一命名空间
让数据从”孤岛”变成”活水”
融科存储通过多协议构建统一命名空间,训练团队可直接拉取推理结果,数据科学家可随时检查训练检查点,生产系统可无缝访问训练数据集。同时支持多团队性能隔离和大规模并行访问,叠加智能重删压缩技术,有效存储密度提升3-5倍。
同一份数据不再需要复制三遍分给三个团队,存储利用率大幅提升,数据管理的复杂度大幅下降。数据孤岛的问题,从架构层面被根治。
04 这不只是一套存储方案
回到开头那个问题:2100万的集群为什么只干了500万的活?
因为行业长期以来把注意力放在了GPU上,而忽视了存储架构是决定AI效率上限的关键变量。
存储介质的结构性短缺,不是一个短期波动,而是一个时代命题。它倒逼每一家做AI的企业重新审视自己的基础设施——不是”买更多”,而是”用更好”。
从算力到存储,从硬件到架构,”智能算力应用创新”不只是一个口号,是对每一个技术环节的重新思考。
存储介质短缺,但AI创新不能等。
在硬件供应的寒冬里,真正的领导者靠架构创新穿越周期。
这是我们给出的答案。